Lab 19: FUN Data Science
Lab 19: FUN Data Science
Instructions
This worksheet serves as a guide and set of instructions to complete the lab.
- You must use the starter file, found here to get credit for the lab.
- There is no additional workbook for this lab. Instead, this worksheet will serve in lieu of the workbook.
Submitting
You will need to fill in the blocks under the starter file and submit this to Gradescope.
- To receive full credit for the coding portion, you will need to complete the required blocks, and the required blocks must pass all tests from the autograder in Gradescope.
- For instructions on how to submit to labs to Gradescope, please see this page.
Please note: you must use the starter file above, and you must NOT edit the name of any of the required blocks. Failing to do either will result in autograder failure.
IMPORTANT: DO NOT use any of the global variables INSIDE of your required function definition. If you do, the autograde may fail, and you will receive 0 credit.
Purpose
The purpose of this lab is to introduce students to the fundamentals of data science through the analysis of environmentally and socially relevant datasets. By working with real-world data, students will gain practical experience in data manipulation, cleaning, and analysis. This lab will help students understand how climate change, pollution, and socioeconomic factors such as income impact the environmental data of different countries and regions.
Objectives
- To introduce students to the basic concepts of data science and data manipulation.
- To teach students how to work with datasets containing multiple variables.
- To develop skills in data cleaning, filtering, and aggregation.
- To analyze trends in environmental data and understand the relationship between climate change, pollution, and socioeconomic factors.
- To encourage critical thinking about the impact of environmental and socioeconomic factors on global and regional scales.
Students will develop a foundational understanding of data science through hands-on experience with environmentally and socially relevant datasets. They will learn to clean, manipulate, and analyze data, drawing meaningful insights about the relationship between climate change, pollution, and socioeconomic factors. This lab will also highlight the importance of data science in addressing global issues and encourage students to think critically about the role of data in solving real-world problems.
By completing this lab, students will be better equipped to tackle more complex data science projects in the future and contribute to the development of solutions for pressing environmental and social challenges.
Importance:
Understanding environmental data and its relationship with socioeconomic factors is crucial in today’s world. Climate change and pollution are pressing global issues that affect every aspect of life, from health to economic stability. By analyzing this data, students can gain insights into how different regions are affected and the underlying causes of environmental degradation. This knowledge is essential for developing strategies to mitigate climate change and improve air quality, thereby contributing to global sustainability efforts.
Social Implications of Environmental and Economic Data
Introduction
As data scientists, it’s crucial to not only analyze data but also understand its broader social implications. The datasets you are working with—average income per country, annual CO2 emissions, population, and air quality—provide a lens through which we can examine pressing global issues. This section explores the relationships between these variables, highlighting how socioeconomic factors influence environmental conditions and vice versa.
Key Concepts and Relationships
- Average Income per Country
- Definition: The average income per capita in a country.
- Social Implications: Average income is a key indicator of a country’s economic health. Higher average incomes often correlate with better access to healthcare, education, and other resources. Conversely, lower average incomes can indicate poverty and limited access to essential services.
- Annual CO2 Emissions
- Definition: The total amount of carbon dioxide emissions produced by a country in a year.
- Social Implications: CO2 emissions are a major contributor to climate change. Countries with high industrial activity typically have higher emissions. However, the impacts of climate change—such as extreme weather events and rising sea levels—disproportionately affect poorer countries that may have lower emissions but are less equipped to mitigate these effects.
- Population
- Definition: The total number of people living in a country.
- Social Implications: Population size affects resource distribution, economic policies, and environmental impact. Larger populations may lead to increased resource consumption and waste production, exacerbating environmental issues, increased CO2 emissions, and an increased Air Quality Index if not managed sustainably.
- Air Quality
- Definition: A measure of the cleanliness of the air, often determined by the concentration of pollutants.
- Social Implications: Poor air quality is linked to numerous health issues, including respiratory and cardiovascular diseases. It’s often worse in poorer countries due to factors like industrial pollution, lack of regulations, and reliance on biomass for cooking and heating.
Observations and Critical Thinking
- The Intersection of Low Income and Air Quality
- In many cases, low income countries experience worse air quality. This is due to various factors, including industrial pollution, inadequate infrastructure, and limited enforcement of environmental regulations. For example, countries with low average incomes may rely more on coal and biomass for energy, leading to higher levels of air pollution.
- The Intersection of High Income and CO2 Emissions
- High-income countries emit significantly more CO2 per person than low-income countries, with the average person in wealthy nations emitting over 30 times as much. Comparing global emissions shares to population shares, high- and upper-middle income countries produce over 80% of global CO2 emissions despite having just under half the world’s population. In contrast, lower-middle and low-income countries, which make up the other half of the population, emit less than 20% of global CO2, with the poorest countries contributing less than 1%. This highlights the disparity in emissions between different income groups.
- Economic Development and Environmental Impact
- There is often a trade-off between economic development and environmental health. Rapid industrialization can lead to increased CO2 emissions and pollution, as seen in many developing countries striving to improve their economic status. However, this growth can come at the cost of environmental degradation and public health.
- Disparities in Environmental Protection
- Wealthier countries typically have more resources to invest in clean technologies and enforce environmental regulations, leading to better air quality. In contrast, poorer countries may struggle to implement such measures, which could result in higher AQI levels and greater health risks for their populations.
- Climate Change Vulnerability
- While wealthier countries are often the largest contributors to CO2 emissions, poorer countries are more vulnerable to the effects of climate change. This includes extreme weather events, food insecurity, and displacement. It’s crucial to consider these disparities when discussing global environmental policies and solutions.
Encouraging Critical Thinking
When analyzing this data, consider the following questions:
- Correlation vs. Causation: Are the observed relationships causal, or might there be other underlying factors?
- Equity and Justice: How do environmental issues intersect with social justice? Who bears the brunt of pollution and climate change, and why?
- Sustainable Development: How can countries balance economic growth with environmental sustainability?
- Global Responsibility: What responsibilities do wealthier, high-emission countries have toward poorer, low-emission countries in combating climate change?
Conclusion
Understanding the social implications of environmental and economic data helps us appreciate the interconnectedness of global issues. As future data scientists, it’s important to approach data analysis with a critical and ethical mindset, considering not only the numbers but also the human stories they represent
Required Blocks
- append columns of data1: _ to data2: _
- filter data: _ with title: _ containing: _
- find average col: _ of data: _
- clean ALL data: _ by removing char: _
- highest value in category: _ from data: _
In addition to required blocks, there are several helper functions that you can use for your solutions to the required blocks!
Note: If you modify your data directly in the functions, you can always reset the data back to the original by going to the “Data” sprite, and clicking the script.
Block 1: append columns of data1: _ to data2: _
Objective:
- Given a data set, data1, write a function that appends another data set, data2 to the columns of data1. Only data1 should be modified, and the original data1 columns should be first with the data2 columns added to the end of data1’s columns. You can assume that data1 and data2 will always have the same number of rows.
Inputs:
- data1: nested list
- data2: nested list
Output:
- Reports a nested list. You can either mutate data1 or report a new list.
Examples
- Example 1:
- Input:
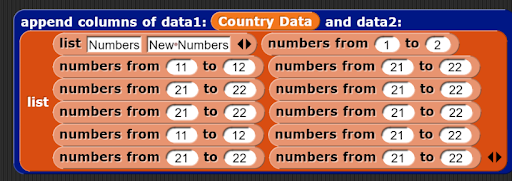
- Output:
- Example 2:
- Input:

- Output:

Block 2: find average col: _ of data: _
Objective:
- Given a data set and a particular column number, find the average of all the data in that particular column. Because the first item in the column is the title of the column / category, you will need to filter that title out. Otherwise taking the average on a word or word and numbers will result in unintended behavior! For this, you will find the “all but first of _” function helpful to use on the input: data.
Inputs:
- col: number
- Represents the column number from the data
- data: nested list
Output:
- Reports a number that is the average
Examples
- Example 1:
- Input:
- Output:

- Example 2:
- Input:
- Output:

Block 3: filter data: _ with title: _ containing: _
Objective:
- Write a function that filters the data set so it only keeps the rows / data field that contain a particular value given a specific column. Your function can return a new list or modify the original.
- We recommend you use “keep”
- IMPORTANT: DO NOT return the titles (the first row in “Country Data”)
Inputs:
- Data: nested list
- Title: string
- Value: string or number
Output:
- Outputs a data set (nested list) where the column of “title” meets the criteria of “value”
Examples
- Example 1:
- Example 2:
- Example 3:


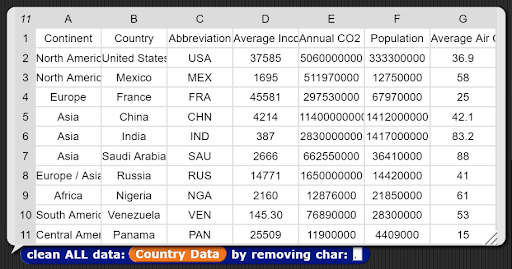
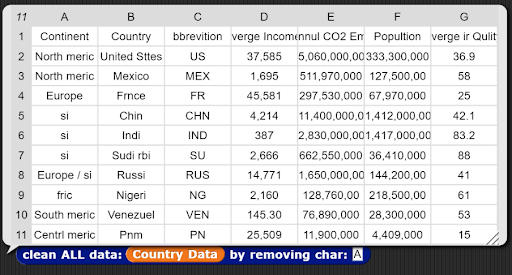
Block 4: clean ALL data: _ data bby removing char: _
Objective:
- Write a function that removes the character from every field in the data set. Your job is to clean the data based on the specified character value. You can either return a new data set or modify the original.
Inputs:
- Data: nested list
- Char: a single character (number, letter, symbol - it will always be one single character)
Output:
- Report a data set that has been “cleaned”
Examples
- Example 1 (removing commas):
- Example 2 (removing the character “A”)
Block 5: highest value in category: _ from data: _
Objective:
- Write a function that finds the highest numerical value from a particular category in our data set. You can assume that the category passed in will always be a number. However, you cannot pass in the title / category itself. So, you will need to use “all but first of” again. Otherwise, you will get unintended results! Hint: You may need to clean your number data before using a block like max.
Inputs:
- Category: a string
- Data: nested list
Output:
- Reports a number
Examples
- Example 1:
- Example 2:
- Example 3:



Once you finish, answer these questions with your partner:
- Which country has the highest average income? Also, which country has the lowest?
- Which country has the highest annual CO2 emissions?
- Which country has the worst average air quality?
All CO2 emission data was collected from: https://ourworldindata.org/co2-emissions
Hannah Ritchie and Max Roser (2020) - “CO₂ emissions” Published online at OurWorldInData.org. Retrieved from: ‘https://ourworldindata.org/co2-emissions’ [Online Resource]
You can always check the validity of your solutions by using the local autograder. Remember to submit on Gradescope!