 :
:
Now that you know that the average length differs, build a simple classifier based on the number of words in a particular message. That is, write a block that takes in a message and, based on how many words it contains, returns either "ham" or "spam" as its classification.


Implement in Snap!, and use it to classify
the messages in our data. You can use a regular loop to call your classify
on the second item in each row of the data, or you might use this
faster method using :
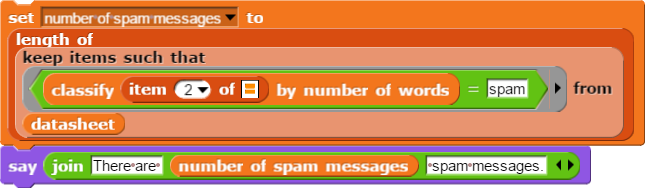
Answer the following questions:
Play around with different threshold values— that is, the number of words above which you decide that a message is spam.
What was the best threshold you found?
How many messages did it classify incorrectly?